Needle-in-Haystack in LongVideo Understanding
—— Re-thinking Temporal Search for Long-Form Video Understanding
1Stanford University 2Northwestern University 3Carnegie Mellon University
We introduce the "Long Video Haystack" task: finding a minimal set of relevant frames (one to five) from tens of thousands of frames for given queries. We provide LV-HAYSTACK, a new benchmark of 3,874 human-annotated instances with fine-grained metrics for keyframe search quality and efficiency. Current methods only achieve a 2.1% temporal F1 score on its LVBENCH subset, highlighting a large gap.
To address this, we propose T*, a lightweight keyframe search framework that reframes expensive temporal search as a spatial search. T* leverages image-based visual localization capabilities and introduces adaptive zooming-in across temporal and spatial dimensions. Under a 32-frame inference budget, T* boosts GPT-4o's performance from 50.5% to 53.1%, and LLaVA-OneVision-OV-72B's from 55.5% to 62.4% on the LongVideoBench XL subset.
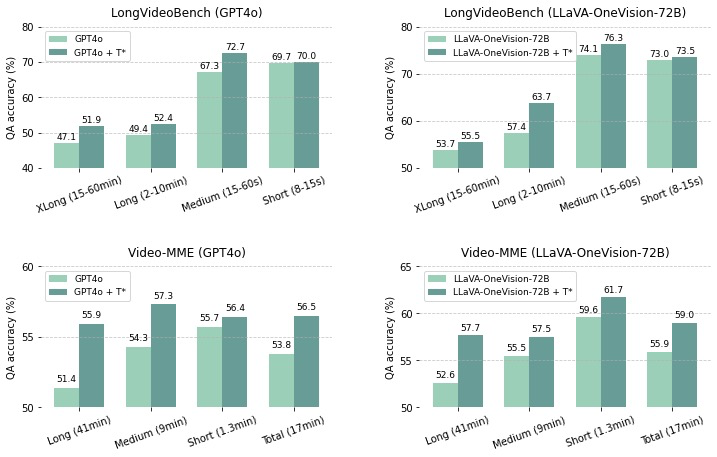
Figure 1. Extrinsic evaluation results demonstrate how T* improves VLMs by selecting 8 keyframes (needle) from a large haystack, highlighting the significance of vision-centric search.
T* is an advanced temporal search framework designed to efficiently identify key frames relevant to specific queries. By transforming temporal search into spatial search, T* leverages lightweight object detectors and Visual Language Model (VLM) visual grounding techniques to streamline the process. T* demonstrates exceptional performance, both with and without additional training, making it a versatile and powerful tool for various applications.
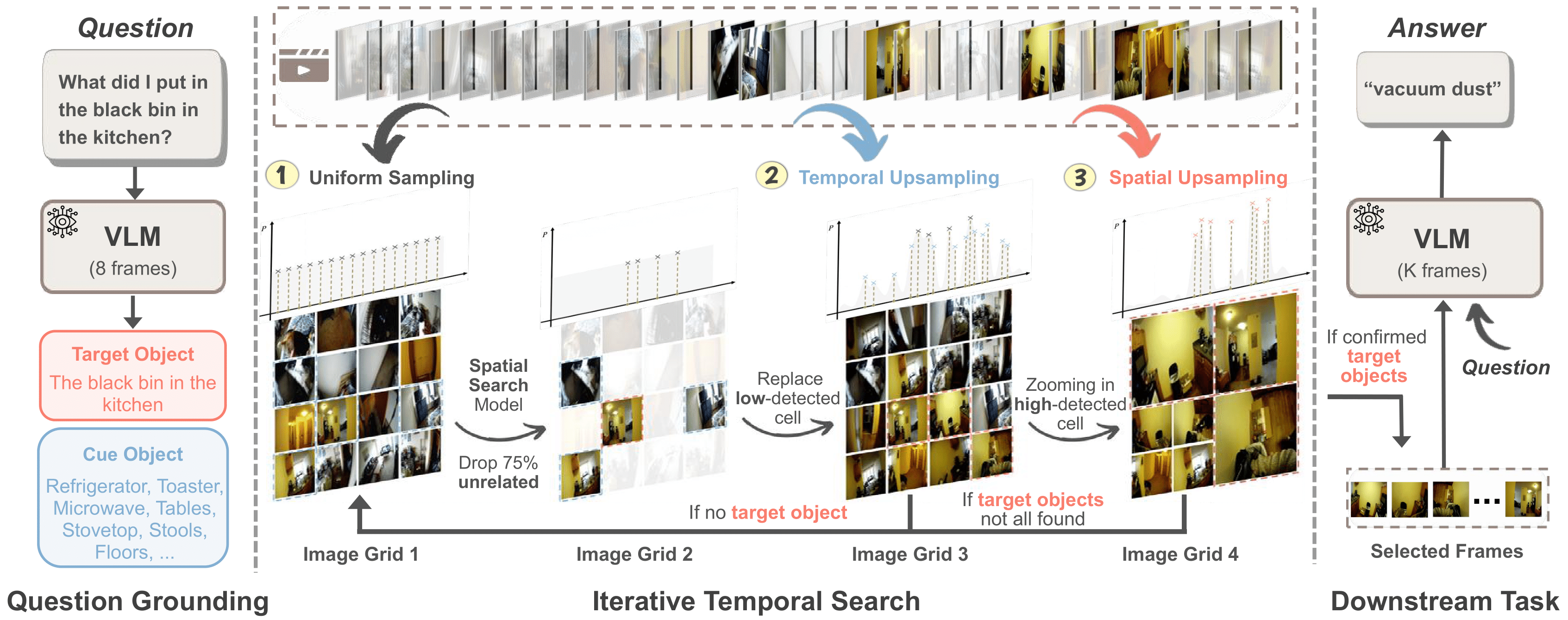
Figure 2. T* employs an iterative temporal search approach to search keyframes essential to answer questions. Left: Question Grounding, where a visual language model identifies visual cues (target and cue object) from the textual question. Center: Iterative Temporal Search, formulated as Spatial Search where a spatial search model iteratively detects visual cues and upsamples relevant temporal/visual regions. Right: Downstream Task, where the visual language model answers questions using K keyframes sampled from the final temporal search distribution as visual input.

Evaluations on Downstream Tasks: Video QA
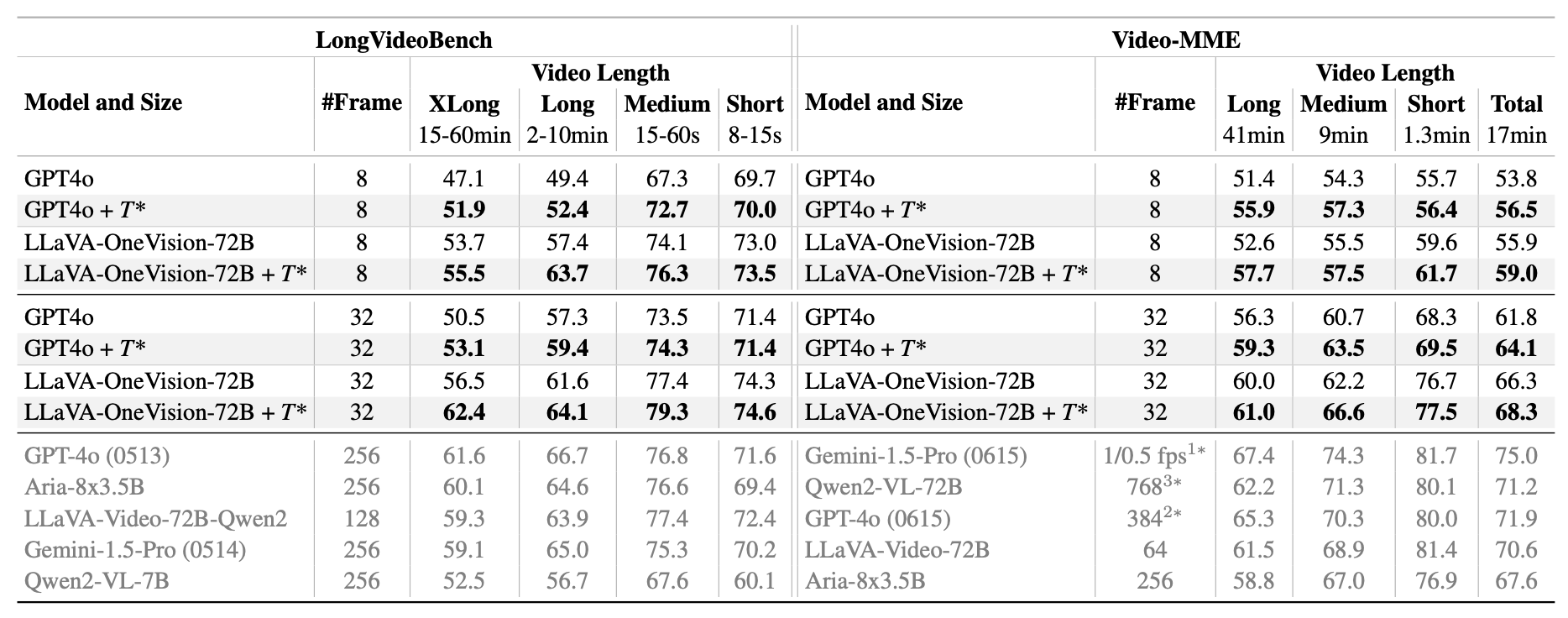
Table 1. Downstream task evaluation results show T* effectiveness as a temporal search module for VLMs on LongVideoBench and Video-MME (without subtitles for fair comparison). Using QA accuracy (%) as the metric, we compare with top leaderboard models (shown in gray), noting these typically use substantially more frames, making direct comparisons challenging. Models are ranked by XLong video performance on LongVideoBench and total score on Video-MME, with frame counts indicated. All baseline figures are directly cited from their original publications.
We explore disentangled evaluation of temporal search & video understanding with 6 fine-grained search metrics.
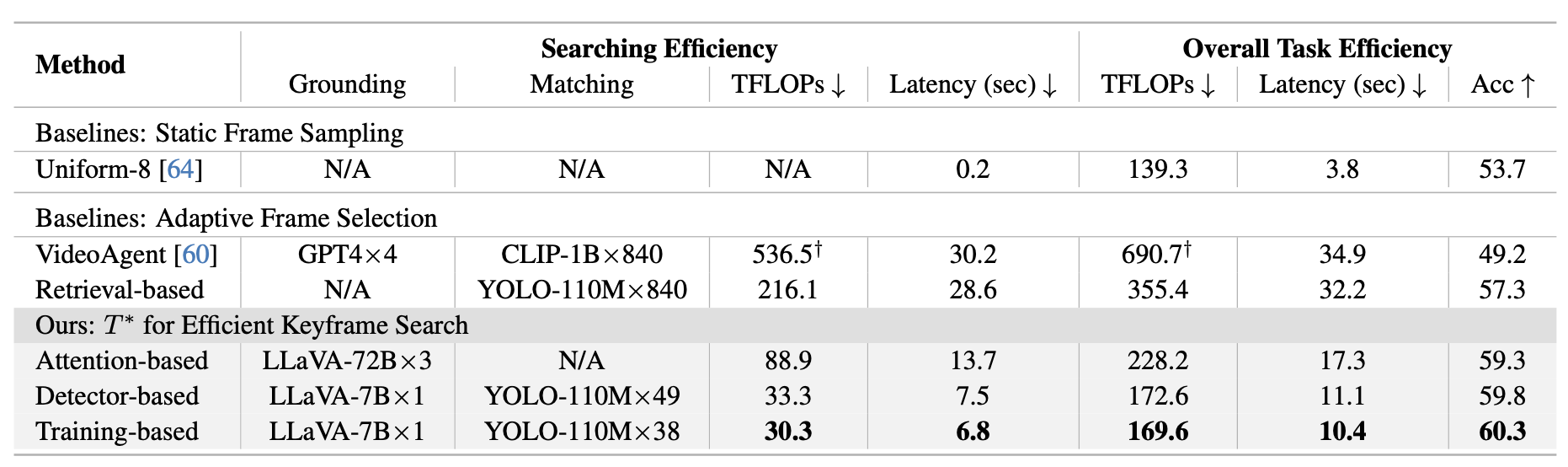
Table 2. Efficiency results on the full LV-HAYSTACK, including search efficiency and overall (search+downstream) efficiency. We report the search models used and their avg. call frequency (e.g., VideoAgent calls GPT-4 four times for grounding). T* achieves high performance with significantly less computation and lower latency. VideoAgent's FLOPs (†) exclude GPT-4 costs due to its closed-source nature.
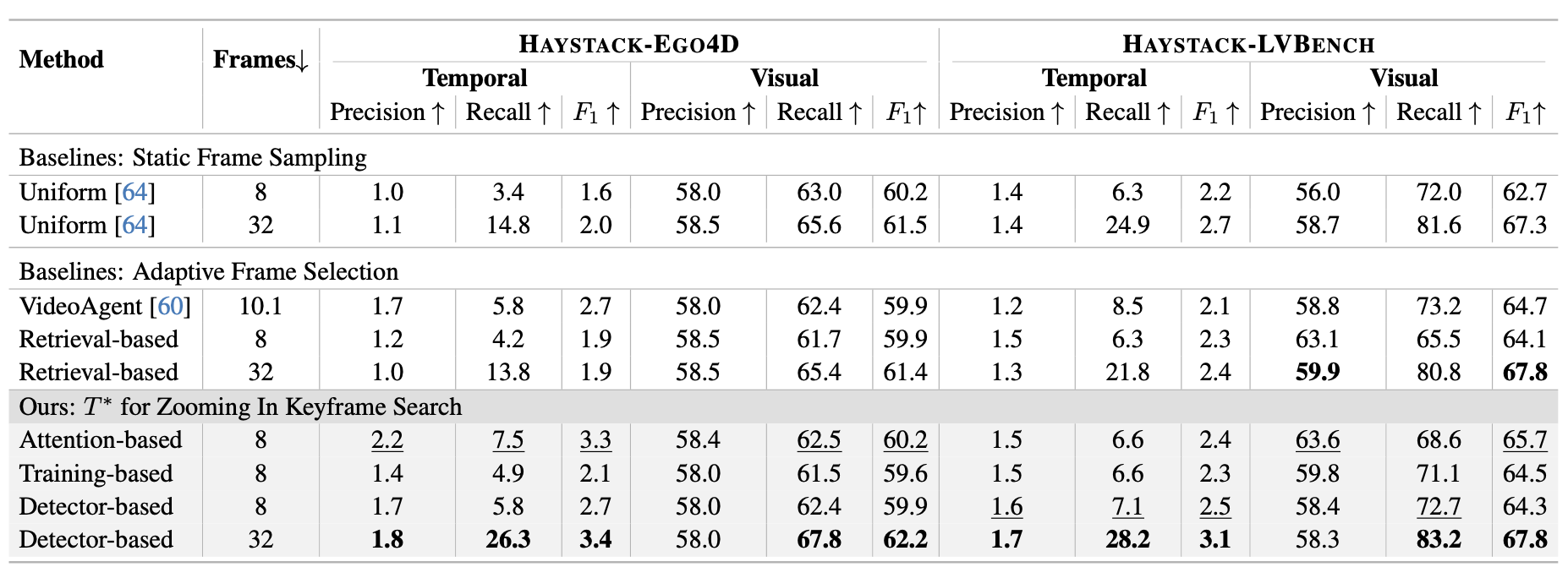
Table 3. Search utility results on LV-HAYSTACK. 8-frame setting bests are underlined, 32-frame setting bests are in bold. We show that more searched frames consistently improves recall but reduces precision in retrieval methods. Detector-based T* achieves best performance in 32-frame setting across metrics, demonstrating the effectiveness of visual grounding and iterative temporal search. Attention-based T* performs well in 8-frame setting but requires larger foundation models, thereby reducing efficiency.

video: 988
length: 423 h (~25.7 min/video)
frame: 45,700,000 (~46,300/video)
QA pair: 15,092 (~15.3/video)
keyframe: 28,300 (~1.9/question)

video: 114
length: 26.7 h (~14.1 min/video)
frame: 2,200,000 (~19,100/video)
QA pair: 342 (~3.0/video)
keyframe: 496 (~1.5/question)
Explore examples from our LV-Haystack dataset. (Note: The video shown in the current interface is not the original dataset video length; it has been clipped to a segment close to the target frame.)
We revisit temporal search for long-form video understanding, focusing on a core challenge for state-of-the-art (SOTA) long-context vision-language models (VLMs). First, we formalize temporal search as a "Long Video Haystack" problem: finding a minimal set of relevant frames (among tens of thousands) given specific queries. To validate this, we introduce LV-HAYSTACK, featuring 3,874 human-annotated instances and fine-grained evaluation metrics for keyframe search quality and efficiency. Experimental results on LV-HAYSTACK reveal a significant gap in temporal search capabilities under SOTA keyframe selection methods. We further propose a lightweight keyframe searching framework, T*, reframing the costly temporal search into a spatial search task. Extensive experiments show that integrating T* into existing methods significantly boosts SOTA performance. We hope LV-HAYSTACK and T* will foster impactful algorithmic advances for efficient long-form video understanding.


